
티스토리 뷰
백준 장학금 챌린지 목표 중 하나인 SQL/DB 강의 수강을 위해 수강한 내용을 블로그에 정리하기로 했다!

📌 관계 데이터 모델과 관계 연산자
✔️ 관계 데이터 구조
▪️ 기본 개념
- 모든 데이터를 테이블로 표현하여 저장
▪️ 릴레이션(relation)
- 테이블을 릴레이션이라 함
- 릴레이션은 속성(attribute)으로 구성 (원자값 or NULL값)
- 다중값 속성(리스트) 허용X

▪️ 관계 데이터베이스 (Relational Database, RDB)
▫️ 스키마
- 관계 스키마 = { 릴레이션 스키마 } = { 테이블 } (ex. '대학' 관계 스키마 = { 학생, 과목, 등록 })
▫️ 데이터
- 관계 데이터베이스 = { 릴레이션 인스턴스 } = { 튜플 }
✔️ 관계 제약
▫️ 건전한 상태
- 데이터베이스(테이블의 집합)에 저장된 데이터가 정확하고 데이터 간의 불일치가 없음
▫️ 데이터베이스의 건전성 유지
- 데이터베이스는 어느 시점에도 항상 건전한 상태를 유지해야 함
- 이를 위해 관계 제약(무결성 제약)매커니즘이 백그라운드에서 실행됨
▫️ 기본키(PK)
- 테이블에서 튜플을 유일(unique)하게 식별할 수 있는 속성의 집합
▫️ 외래키(FK)
- 어떤 테이블의 기본키(PK)에 있는 값만을 갖는 속성의 집합
- 외래키는 기본키가 아님 but 기본키이면서 동시에 외래키인 경우도 있음(PK/FK)
▫️ 부모-자식 테이블
- 자식 테이블 : FK가 정의된 테이블 (FK를 통해 PK를 참조)
- 부모 테이블 : FK가 참조하는 PK가 정의된 테이블
▪️ 무결성 제약
▫️ 개체 무결성
: 기본키(PK)값은 유일하며, 널 값을 가질 수 없음(NOT NULL)
▫️ 참조 무결성
: 외래키(FK)값은 부모 테이블의 기본키(PK)값과 같거나 NULL 값을 가짐
✔️ 관계 대수
- 릴레이션 조작(ex. 검색 갱신)을 위한 대수 연산자
- 관계 대수에서 피연산자는 릴레이션이고, 연산의 결과도 릴레이션
▫️ 폐쇄 성질
- 피연산자와 연산 결과가 모두 같은 데이터 타입(테이블)이어야함
- 중첩된 수식의 표현이 가능
1️⃣ 집합 연산자
▪️ 합집합 ∪
▪️ 교집합 ∩
▪️ 차집합 -
▪️ 카티션 프로덕트 ×
: 두 릴레이션에 속한 모든 튜플을 각각 접속(concatination)시킨 튜플로 이루어진 릴레이션
✔️ ∪, ∩, -연산의 피연산자들은 (1) 차수(속성의 갯수)가 같아야 함 (2) 대응하는 속성 별로 도메인이 같아야 함
✔️ ∪, ∩, × 연산은 결합적(결합 법칙O) + 교환적(교환 법칙O)
❕ 릴레이션(R)의 수학적 표현
- R(A1, A2, A3, ..., An) (Ai는 속성이며 대응하는 도메인 Di가 있음)
2️⃣ 순수 관계 연산자
▪️ 셀렉트 - 조건에 만족하는 튜플을 반환
: SQL 검색문의 WHERE 절!

▪️ 프로젝트 - 타겟 속성리스트를 반환
: SQL 검색문의 SELECT 절!

❕ 결과에 중복된 튜플은 제거
▪️ 조인 - 카티션 프로덕트에 기반한 연산
: SQL 검색문의 FROM 절!
▫️ 세타조인

▫️ 등가조인

▫️ 자연조인 (일반적으로 조인은 자연조인을 의미)

3️⃣ 확장된 관계 연산자
▪️ 외부 조인
: 조인할 양쪽 릴레이션에서, 조인 결과에 포함되지 않는 튜플도 대응하는 튜플 속성 값을 모두 NULL값으로 만들어서 결과에 포함
: left (outer) join, right (outer) join, full (outer) join
▪️ 그룹 연산과 집계 연산
▫️ 그룹 연산
: 기준 속성 값이 같은 튜플끼리 그룹핑 (ex. Group학년(학생))
: 집계 연산을 위한 전처리로 많이 사용!
▫️ 집계 연산
: 기준 속성 값에 대해 통계치(COUNT, AVG, MIN, MAX, STDDEV, VARIAN)를 계산
❕ 기준 속성에 NULL값이 들어있는 튜플은 계산에서 제외
❕ 기준 속성에 중복값이 있는 튜플도 계산에 포함
▪️ 작명 연산
: 중각 결과 릴레이션에 이름을 붙이고, 그것의 속성 명칭을 변경하는 기능

📌 다양한 ERD 표기법
✔️ ERD에서 표현하는 내용
- 테이블의 구조
- 테이블 간의 관계 (by PK/FK 컬럼)
✔️ 관계의 특성 (인스턴스 레벨)
▪️ 매핑 정보
: 일대일(1:1), 일대다(1:n), 다대다(n:m)
❗ 다대다 매핑은 두 개의 일대다 매핑으로 표현(중간 테이블 도입)
▪️ 참여 정보
: 부분 참여, 전체 참여

✔️ 관계의 종류
▪️ 비식별 관계
: FK값을 PK값으로 가지지 않는 관계 (점선으로 표현)
▪️ 식별 관계
: FK값을 PK값으로 가지는 관계 (실선으로 표현)
: (1) 존재 종속 관계이거나 (2) 다대다 매핑일 경우 식별 관계를 형성
🙋🏻♀️ 존재 종속 관계?
💡 어떤 튜플(b)의 존재가 다른 튜블(a)의 존재에 달려있음! a는 주 튜플, b는 종속 튜플이라고 함!
종속 테이블은 관계에 항상 전체 참여함!
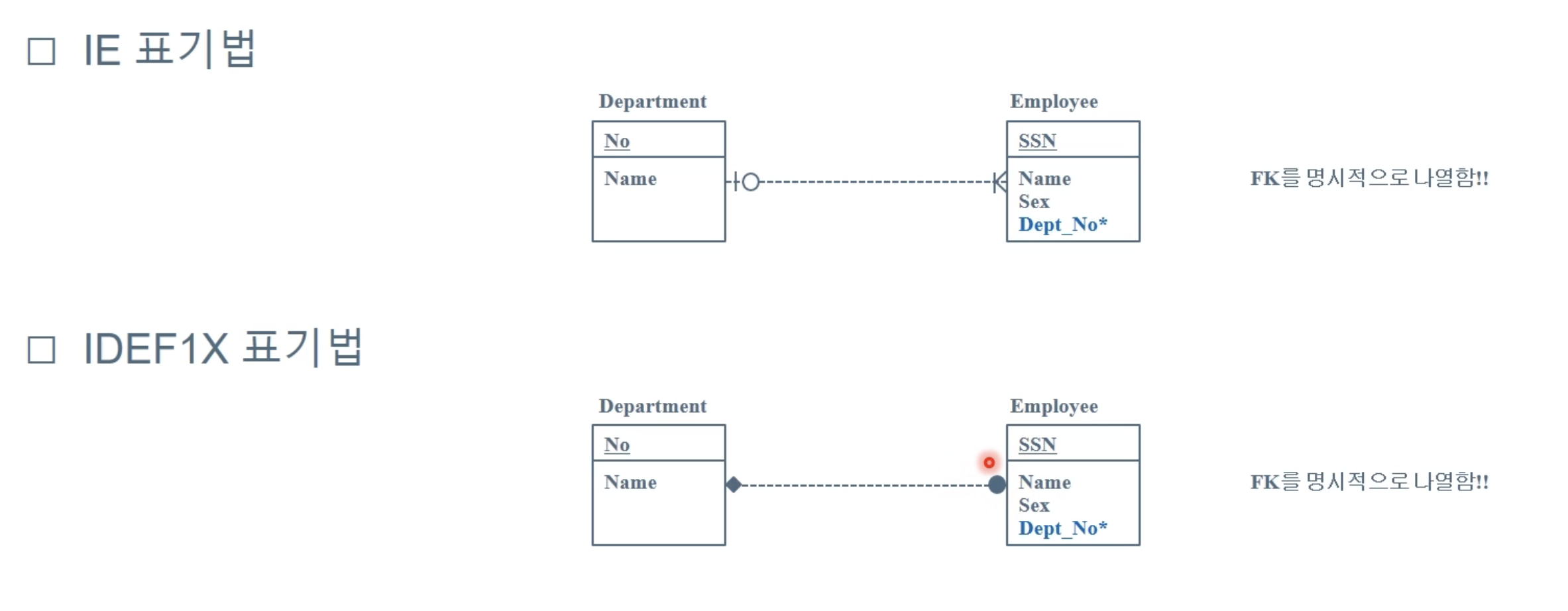
✔️ ERD 표기법
1️⃣ IE 표기법 (ex. MySQL Workbench)
2️⃣ IDEF1X 표기법
: 부모 테이블의 참여 형태는 표현 X
📌 스키마와 테이블 정의
✔️ SQL 표준
: SQL 표준은 기능을 명세. 따라서 벤터별(ex. MySQL, MariaDB, SQL Server 등)로 표준과 다른 용어를 쓰는 것이 허용
: 제조사는 SQL 표준의 기능을 선택적으로 구현
: 일반적으로 벤터별로 SQL 문법의 차이는 적어지고 있으나, 데이터 타입과 내장 함수에서는 여전히 차이가 많음!
❕ DBMS의 교체가 항상 가능하도록, 이식성이 보장된 응용 프로그램을 작성! (특정 제품 고유의 기능보다는, 가능하면 표준 기능만을 사용!)
✔️ SQL 데이터 타입
▪️ 숫자형
- 정수형: INTEGER, SMALLINT, ...
- 실수형: DECIMAL(p,s), FLOAT, REAL, DOUBLE (p: 전체 자릿수, s: 소수점 이하 자릿수)
▪️ 문자형
- 고정길이 문자열: CHAR(n)
- 가변 길이 문자열: VARCHAR(n)
▪️ 날짜형
- DATE
- TIME
- TIMESTAMP: DATE & TIME
- INTERVAL
🔎 MySQL의 데이터 타입 🔎
▪️ 숫자형
▫️ 정수형
- TINYINT: 1 byte
- SMALLINT: 2 bytes
- MEDIUMINT: 3 bytes
- INT: 4 bytes
- BIGINT: 8 bytes
▫️ 실수형
- DECIMAL(p,s)
❕ 컬럼의 디폴트 부호 특성은 SIGNED
▪️ 문자형
▫️ 고정길이 문자열
- CHAR(n): data (최대 255문자, n은 문자 갯수)
▫️ 가변길이 문자열
- VARCHAR(n): 1 or 2 byte prefix + data (최대 65,535 문자, prefix는 n값을 기록)
💁🏻♀️ CHAR(n)와 VARCHAR(n)의 차이가 정확하게 뭐죠?
👩🏻🏫 CHAR(n)을 쓰면 데이터를 저장할 때 우측의 남는 공간을 공백 문자로 채움! 검색 시 결과값에서 공백을 제거(MySQL)
VARCHAR가 CHAR에 비해 작은 공간을 사용하지만 CHAR에 비해 접근 속도가 약간 느려질 수 있음!
❕ CHAR()나 VARCHAR(n)에서 입력 데이터가 n보다 클 경우, 넘치는 부분은 truncate됨!
▫️ TEXT 문자열: VARCHAR(n)과 동일 but n은 미리 할당된 값을 사용
- TINYTEXT: 1 byte prefix + data (최대 255 문자)
- TEXT: 2 byte prefix + data (최대 65,535 문자)
- MEDIUMTEXT: 3 byte prefix + data (최대 16,777,215 문자)
- LONGTEXT: 4 byte prefix + data (최대 4,294,967,295 문자)
▫️ ENUM(a, b, c, ...): 나열형 (enumeration)
- 나열된 문자열 중 단 하나의 문자열만 갖는 타입
▫️ SET(a, b, c, ...): 나열형 다중값
- NULL을 포함하여 1개 이상의 문자열을 갖는 타입. 값들을 ","로 구분
❕ PK나 FK에는 ENUM과 SET 타입을 사용할 수 없음
▪️ 이진 문자형
▫️ 고정길이 이진 문자열
- BINARY(n): data (최대 255 바이트)
▫️ 가변길이 이진 문자열
- VARBINARY(n): 1 or 2 byte prefix + data (최대 65,535 바이트)
▫️ BLOB (binary large object)이진 문자열: VARBINARY(n)과 동일 but n은 미리 할당된 값을 사용
- TINYBLOB: 1 byte prefix + data (최대 255 바이트)
- BLOB: 2 byte prefix + data (최대 65,535 바이트)
- MEDIUMBLOB: 3 byte prefix + data (최대 16,777,215 바이트)
- LONGBLOB: 4 byte prefix + data (최대 4,294,967,295 바이트)
▪️ 날짜형
▫️ YEAR (yyyy)
▫️ DATE (yyyy-mm-dd)
▫️ TIME, TIME(fsp) (hh:mm:ss[.fraction])
▫️ DATETIME, DATETIME(fsp) (yyyy-mm-dd hh:mm:ss[.fraction])
▫️ TIMESTAMP, TIMESTAMP(fsp) (yyyy-mm-dd hh:mm:ss[.fraction])
- 디스플레이 형식은 DATETIME과 동일
- 실제로는 unix epoch 부터의 초의 갯수(카운터)
- DATETIME에 비해 저장 공간을 줄일 수 있음(5바이트 → 4바이트)
❕ SQL 표준에서의 용어
: 릴레이션(relation) → 테이블(table)
: 속성(attribute) → 컬럼, 열(column)
: 튜플(tuple) → 행(row)
❗ SQL 명령문의 종류?
▪️ 데이터 정의문(DDL)
: CREATE, DROP, ALTER
▪️ 데이터 조작문(DML)
: INSERT, DELETE, UPDATE, SELECT
▪️ 데이터 제어문(DCL)
: GRANT, REVOKE
▪️ 트랜젝션 제어문(TCL)
: COMMIT, ROLLBACK, SAVEPOINT
✔️ SQL DDL 명령어
▪️ 스키마 관련
1️⃣ CREATE SCHEMA
CREATE SCHEMA wtwt;
CREATE DATABASE wtwt;2️⃣ DROP SCHEMA
▪️ 테이블 관련
3️⃣ CREATE TABLE
: 테이블의 구조와 컬럼의 제약조건을 명세
❗ 컬럼 제약 조건
- NOT NULL
- UNIQUE [KEY]: 고유한 값을 갖거나 NULL (내부적으로 저장장치에 인덱스를 생성하라는 명령)
- PRIMARY KEY: UNIQUE and NOT NULL
- FOREIGN KEY: 부모 테이블의 PK값 or NULL
- CHECK: 입력/수정 가능한 값의 범위를 제한하는 논리식
❕컬럼 제약조건의 서술 위치에 따라 (1) 컬럼 레벨 정의 방식, (2) 테이블 레벨 정의 방식으로 나뉨!
💁🏻♀️ 테이블 레벨 정의방식?
💡 NOT NULL을 제외한 모든 제약조건(UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK)을 정의
💡 조건명을 사용할 수 있음 → 제약 조건의 삭제/추가 가능! (수정은 불가능!)
💡 일반적으로 NOT NULL을 제외한 모든 컬럼 제약조건에 권장!
CREATE TABLE users
(
user_id BIGINT NOTNULL,
nickname VARCHAR(10) NOTNULL,
password VARCHAR(255) NOTNULL,
gender ENUM(MALE, FEMALE, NONE),
birthday DATE,
profile_image BIGINT NOTNULL,
CONSTRAINT pk_user
PRIMARY KEY (user_id),
CONSTRAINT fk_user_image
FOREING KEY (profile_image) REFERENCES images(image_id),
CONSTRAINT chk_birthday
CHECK (birthday >= '1900-01-01')
);❕하나의 컬럼에만 적용되는 CHECK 제약조건은 column constraint로 서술 가능 (여러 컬럼에 적용되는 조건은 table constraint로!)
birthday DATE CHECK (birthday >= '1900-01-01')
❕제약조건 명칭의 Namespace
- 표준 SQL : NOT NULL을 제외한 모든 제약조건이 같은 namespace에 속함
- MySQL : 제약조건 별로 namespace가 존재
❕생성된 테이블의 구조 확인
DESCRIBE users;
❕SELECT 문을 이용한 테이블 생성 + 데이터 삽입 (MySQL, Oracle)
CREATE TABLE users_temp AS
SELECT *
FROM users;: 새로운 테이블을 생성하고, SELECT 문의 결과를 새로운 테이블에 삽입
: 기본 제약조건 중 NOT NULL 제약조건만 생성되는 테이블에 적용 (PRIMARY KEY, FOREIGN KEY, UNIQUE, CHECK 제약조건은 모두 사라짐)
❕SELECT 문을 이용한 테이블 생성 + 데이터 삽입 (SQL Server)
SELECT *
INTO users_temp
FROM users;
4️⃣ DROP TABLE
: 테이블 정의와 테이블 데이터를 모두 삭제
: 참조 무결성을 위해 RESTRICT(거부) | CASECADE(함께 삭제) 옵션 제공 (부모 테이블을 삭제할 때 실행하는 제약 조건)
🔎 MySQL
: RESTRICT | CASECADE 옵션과 관계없이, 자식 테이블이 한 개라도 있으면, 테이블(부모 테이블)에 대한 삭제 거부
DROP TABLE users;
5️⃣ ALTER TABLE
: 컬럼의 추가/삭제/수정 or 제약조건의 추가/삭제
ALTER TABLE users
ADD COLUM name VARCHAR(10);: FIRST/AFTER 절이 없으면, 디폴트는 'AFTER 마지막_컬럼명'
❕ 컬럼을 수정하는 것은 기존 데이터를 고려해야 하므로 제한적! (수정 후에도 기존 데이터는 영향을 받지 않아야 함)
- 기존 데이터가 있으면, 컬럼의 크기를 늘릴 수는 있지만 줄이지는 못함
- 컬럼이 NULL 값만 가지고 있거나 테이블에 아무 행도 없으면 컬럼의 크기를 줄일 수 있음
- 컬럼이 NULL 값만을 가지고 있으면, 데이터 타입을 변경할 수 있음
- 컬럼의 DEFAULT 값을 바꾸면, 변경 작업 이후 발생하는 행 삽입에만 영향을 미침
- 컬럼에 NULL 값이 없을 경우에만, NOT NULL 제약조건을 추가할 수 있음
ALTER TABLE users
MODIFY COLUMN profile_image BIGINT NOT NULL DEFAULT '0';ALTER TABLE users
ADD CONSTRAINT chk_nickname
CHECK (chk_nickname LIKE 'nickname_%')
6️⃣ RENAME TABLE - MySQL, Oracle 등 일부 DBMS에서만 제공
RENAME TABLE users TO user;
7️⃣ TRUNCATE TABLE
: 테이블 정의는 그대로 두고, 테이블 데이터를 모두 삭제
: 내부적으로는 DROP TABLE문 실행 후, CREATE TABLE 문을 통해 테이블을 다시 생성
TRUNCATE TABLE users; /* 자식이 있으면 실행 거부! */
💁🏻♀️ DDL과 DML의 차이?
▪️ DDL의 테이블/튜플 삭제 명령어
- 트랜젝션 로그에 실행 기록을 남기지 않음 (시스템 부하↓)
- DDL 명령이 실행되는 즉시, 해당 작업이 완료됨 (AUTO COMMIT)
- Rollback을 통한 데이터 복구 불가
▪️ DML의 튜플 삭제 명령어
- 테이블 정의는 유지, 데이터(튜플)만 삭제
- 트랜젝션 로그에 실행 기록을 남기므로, 시스템 부하↑
- COMMIT 명령을 실행하여, 로그에 기록된 명령을 하드디스크의 테이블에 실제로 반영
- Rollback을 통한 데이터 복구 가능
📌 단일 테이블 검색문1
✔️ SELECT 문
SELECT [ALL|DISTINCT] {{컬럼 [AS] 컬럼+별칭}* | *} /* project, 집계 연산자 */
FROM 테이블_리스트 /* join 연산자 */
[WHERE 튜플_조건식] /* select 연산자 */
[GROUP BY 컬럼명 [HAVING 그룹_조건식]] /* group 연산자 */
[ORDER BY {컬럼명|컬럼_별칭|컬럼_위치 [ASC|DESC],}+]
[LIMIT [offset,] row_count]: MySQL, SQL Server의 경우 FROM절도 생략OK
: 실행 순서는 (1) FROM절 → (2) WHERE 절 → (3) GROUP BY 절 → (4) HAVING 절 → (5) SELECT 절 → (6) ORDER BY 절 → (7) LIMIT 절
SELECT *
FROM users;SELECT user_id, nickname 닉네임
FROM users
WHERE gender = 'FEMALE';❕ 출력 테이블의 형태에 따른 분류
- 다중행 질의(table query) : 실행 결과가 n-tuple의 집합
- 다중값 질의(column query) : 실행 결과가 scalar value(1-tuple)의 집합
- 단일값 질의(scalar query) : 실행 결과가 1개의 값(scalar value = 1-tuple 1개로 이루어진 집합)
▪️ SELECT 문의 SELECT절
: 검색 결과 출력할 컬럼들(컬럼 리스트)를 명세
: 관계 대수의 project 연산자
SELECT [ALL|DISTINCT] {{컬럼 [[AS] 컬럼_별칭],}+ | *}
FROM 테이블_리스트- ALL : 중복된 튜플을 모두 포함(Default)
- DISTINCT : 중복된 튜플은 하나만 남겨두고 모두 제거
- 컬럼 별칭 : 컬럼에 출력용 별칭을 부여할 수 있음, 컬럼명 대신 컬럼 표현식이 사용될 때 유용 (컬럼 별칭에 공백이 필요하면 따옴표를 사용!)
❕ 표준 SQL에서, 컬럼 별칭은 WHERE절, GROUP BY 절에 사용X (SELECT절, ORDER BY 절에는 사용O)
❕ MySQL에서는 GROUP BY(HAVING)절에서 허용! (WHERE절에서는 사용X)
SELECT quantity * priceEach 주문액
FROM orderDetails
WHERE quantity * priceEach >= 2000; /* 주문액 >= 2000 불가! */
❕ WITH절을 이용해 임시 테이블을 만들고, 두 검색문을 연결할 수 있음!
: 주 검색문의 실행이 완료되면, 임시 테이블은 삭제됨
: 관계 대수의 rename 연산자 (중간 결과 저장)
WITH temp AS
(
SELECT quantity * priceEach 주문액
FROM orderDetails
)
SELECT 주문액
FROM temp
WHERE 주문액 >= 2000;
❕컬럼 별칭의 용도
1️⃣ 기존 컬럼의 출력용 명칭을 정의 (ex. 영문 컬럼명을 한글 컬럼명으로 대체)
2️⃣ 산술 표현 식을 사용한 컬럼 생성 (quantity * priceEach 주문액)
3️⃣ 문자열 연결을 이용한 컬럼 생성 (CONCAT(firstName, ' ', lastName) 이름)
4️⃣ CASE 표현식을 사용한 컬럼 생성
💁🏻♀️ CASE 표현식?
: SELECT 절에서 IF-THEN-ELSE 논리와 유사한 기능 제공 (중첩OK)
: 기존 컬럼의 값을 변경하거나, 새로운 컬럼을 생성하는데 사용
SELECT user_id, nickname,
CASE gender
WHEN 'FEMALE' THEN '여자'
WHEN 'MALE' THEN '남자'
ELSE '알수없음'
END AS gender
FROM users;
▪️ 검색문의 WHERE절
: 테이블에서 튜플 조건식이 true인 튜플만 선택(조건에 맞는 튜플만 필터링)
: 관계 대수의 select 연산자
❗ 조건식에 들어가는 연산자의 종류
1️⃣ 비교 연산자
: >, >=, <, <=, =, <> (!=)
2️⃣ SQL 연산자
- SQL 문장을 프로그래밍 언어가 아니라, 일반 영어 문장과 비슷하게 보이도록 함
- SQL 문장을 짧게 만들어주며, 성능 측면에서도 장점O
: BETWEEN a AND b / NOT BETWEEN a AND b
SELECT *
FROM users
WHERE rate BETWEEN 3 AND 5;: IN (list), NOT IN (list)
SELECT *
FROM users
WHERE nickname in ('uijin._.j', 'seyeoonny');: LIKE str / NOT LIKE str
SELECT *
FROM posts
WHERE text LIKE '%검색어%' OR
title LIKE '%검색어%';: IS NULL / IS NOT NULL
💁🏻♀️ NULL 값?
: 값이 존재하지 않는 것을 표현할 때 사용 (ASCII 코드 00: NULL)
: 어떤 값과도 계산(결과는 NULL)하거나 비교(결과는 FALSE)할 수 없음
SELECT *
FROM users
WHERE profile_image IS NULL;
3️⃣ 논리 연산자
: (), NOT,AND, OR (이 순서대로 먼저 처리)
❕비교 연산자 및 SQL 연산자가 논리 연산자보다 우선 처리!
'DB' 카테고리의 다른 글
| [DB/SQL기초] 내일배움코스 후기 (0) | 2023.08.29 |
|---|---|
| [MySQL] 설치 + 간단한 명령어 (0) | 2023.08.16 |
| [SQL/DB기초] 5주차 정리 (0) | 2023.08.15 |
| [SQL/DB기초] 4주차 정리 (0) | 2023.08.13 |
| [SQL/DB기초] 3주차 정리 (0) | 2023.08.06 |